There is a problem with traditional coding interviews: they don’t measure what you hope they do.
Companies want to hire people that will do high quality work efficiently. For engineers, this involves values, taste, system design, collaboration, programming, and other skills. This is a lot! So your assessment better represent the real work of a job well, or else you will filter out people that might thrive and hire people who are a poor fit.
The problem is that you want a repeatable, scalable process in hiring. This means reducing down questions to basic forms. For software engineering, this means a basic coding question. The code is often trivial.
For example, print out “fizz” and “buzz”, alternating, and repeat to match the fibonacci sequence. This is slightly more complicated than a basic FizzBuzz. Here is one solution.
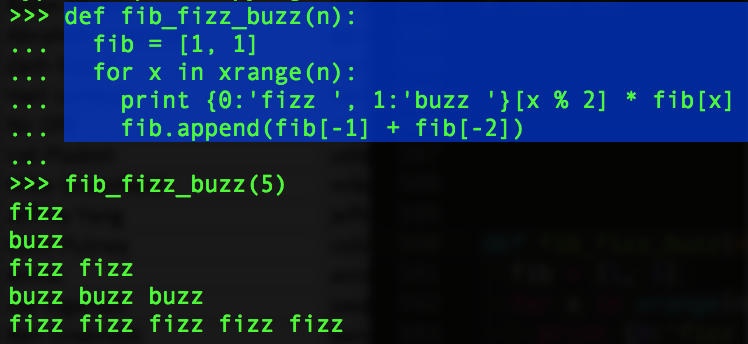
A more sophisticated interviewer might ask where this will fail. In this case, the fib array grows without bounds, so for large input values, you’ll run out of memory. Nevermind that the task requires exponentially increasing printing.
The point is that this question has no point. It has no meaning or purpose. You can dork out over different approaches and their limitations, but you aren’t learning much about candidates.
When it comes to assessing specialized knowledge (for example we’re hiring for mobile and data focused engineers), this is terrible assessment.
There are other problems too. People rarely write code on a wall, no matter what The Social Network tells you. People rarely write code under tight time pressure, where a minute of silence would flunk. More complicated problems routinely involve long blocks of uninterrupted times, so much that we call it the “maker schedule”. And then there is Google. Everyone, even great programmers, constantly look up answers to questions.

At YesGraph, we’re hiring engineers focused on data and machine learning. We needed to come up with something else.
So instead of a programming interview, we’re making a take-home problem focused on a real machine learning challenge.
This is better in a few ways. The problem is realistic, if confined. We removed only some of the data gathering and cleaning typically involved in learning. Candidates will produce significant code that actually looks like the code someone would write in production. It tests high level knowledge of learning. If you have no experience, you probably won’t know where to even start. But it also allows for differentiation and personality, so that great candidates can shine. The problem is asynchronous, so people can do it when they feel up to it. It also allows people to work in their familiar development environment. The problem is complex enough that it assesses communication and reporting as much as coding.
There are still some limits that aren’t perfect. It takes hours not days. Most complex projects don’t take hours. We don’t help someone come up with an answer, so we’re not testing collaboration. It only involves one or two kinds of problems, so it doesn’t measure breadth of knowledge.
For those things, we’re relying on a Q&A format, where we probe deep into someone’s experience and knowledge. There we’ll look at how well they communicate in addition to how much domain knowledge they have.
I bet a lot of people reading this are curious about the test. If you can promise not to share it, email ivan@yesgraph.com and I’ll give it to you.
I’ll publish it here on this blog after a while of using it. We want to balance establishing a baseline for future interviews and sharing with the community, like this post! So we’ll periodically retire and publish our problems.